
Kris Dickinson
Director, Financial Services
Along with this, the datasets in financial institution data servers are spread across several systems and business units which involves managing different data formats and data fragmentation scenarios to prepare a single source of truth to aid the data analysis use cases for fintech innovation.
Several other datasets regarding consumer demographics and behaviour may be available for purchase but come with hefty price tags. Moreover, real-life datasets do not provide flexibility in running specific scenarios that may require tweaking datasets to meet the requirements of a specific use case that needs to test extreme conditions such as market crashes or app failures.
What is the modern approach to data?
It is quite apparent that to meet the massive requirements of data for innovation, the financial services industry needs a new approach. That is where the concept of digital twins comes into play. Digital twin in banking involves the usage of synthetic data generators which use machine learning algorithms and statistical simulations to mimic the statistical properties of real-life datasets. The synthetic datasets of Digital Twin also allow fintechs to generate dynamic datasets that can create projections for multiple future scenarios incorporating alternate market, business, and lifestyle events.
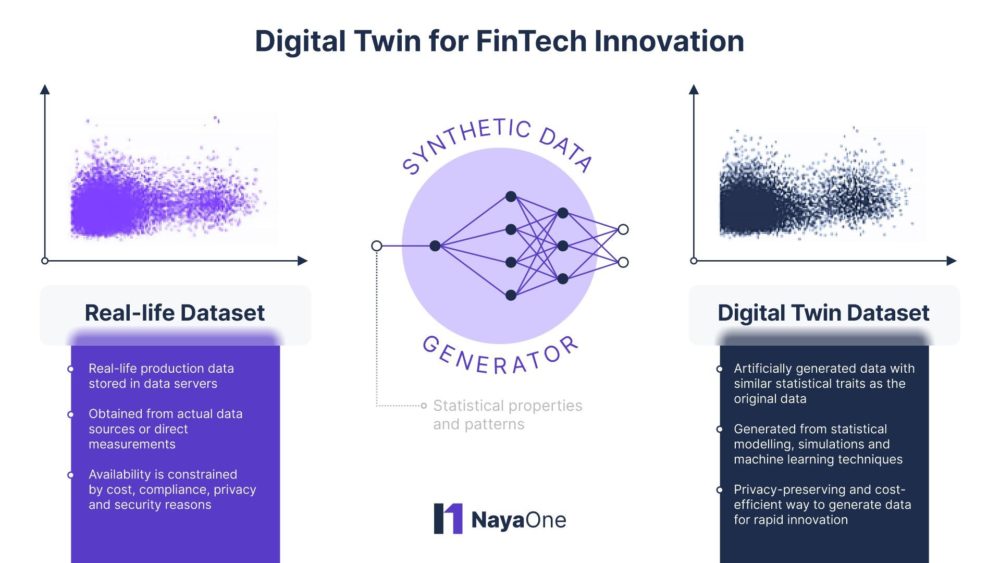
Synthetic data generators essentially create new datasets that have all the same statistical characteristics and patterns as the real data but are secure in a manner that it is completely impossible to trace or recreate the original datasets by using either synthetic datasets or synthetic generators. Hence, the digital twin in banking datasets have the same utility and relevance for innovative use cases as the original datasets, but none of the security and privacy concerns that are associated with using real-life data sets.
Digital twin in banking to accelerate fintech innovation
Digital Twin unlocks a new archetype for creating or sharing data quickly and securely to accelerate the experimentation and validation of commercial innovations in the financial services industry.
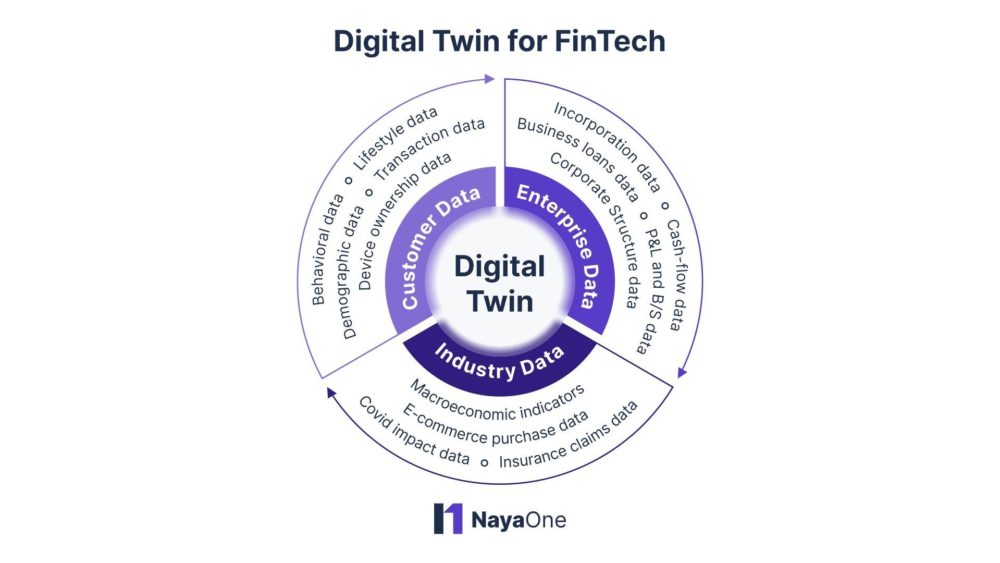
It allows fintechs to access several kinds of data such as consumer data, enterprise data, and industry data to test and validate their innovative solutions. The speed and scalability of generating synthetic datasets are due to extra value-additions that help fintechs reduce the time to market and allow them to experiment with various alternate scenarios cost-effectively.
Digital Twin also allows the flexibility to inject multiple scenarios to generate different dynamic datasets to test out a gamut of alternate scenarios during development and quality assurance stages to ensure innovation use cases perform well in various real-life scenarios and business events.
Digital twin in banking for open and collaborative innovation
As the fintech industry matures both in terms of customer adoption and regulatory acceptance, it has given rise to fintech infrastructure startups that are enabling both incumbents and insurgents to launch new products and services. These fintech infrastructure startups are innovating across several use cases such as digital onboarding, credit underwriting, claims management, KYC, robo-advisors, card processing, digital compliance, etc.
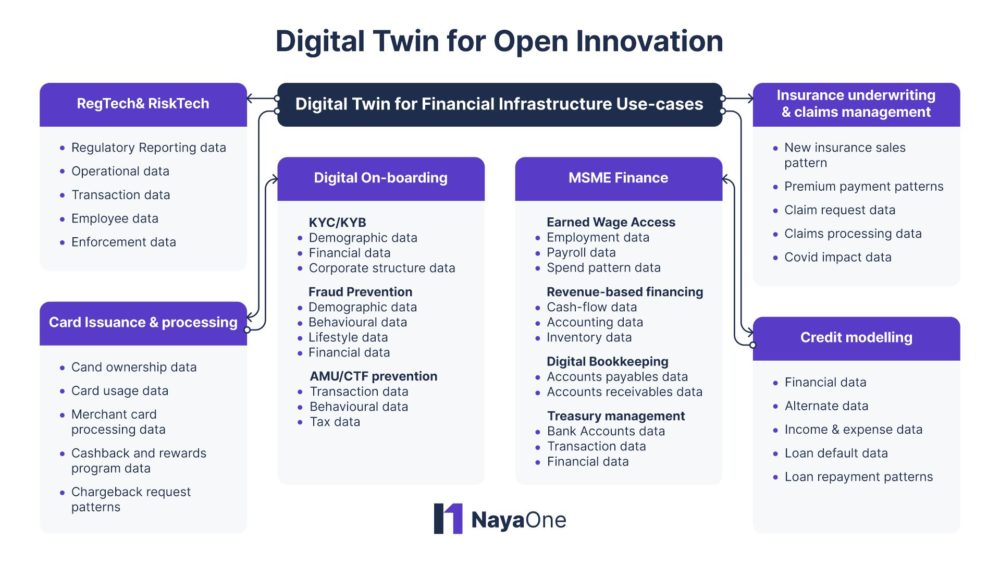
NayaOne’s Digital Twin offering promises to be an excellent solution to serve this growing segment of FinTech infrastructure capability providers. It allows fintech startups to test their solutions quickly and securely while unlocking the doors to collaborate with financial institutions, which may find it difficult to share their data with the fintechs, owing to their compliance imperatives or legacy technology constraints.
The availability of ready-to-use synthetic datasets also helps fintechs control the number of people required to prepare data for experimentation and enables them to innovate freely without worrying about data leakage risks.
Partnering with NayaOne for Digital Twin Solutions
NayaOne’s Digital Twin offering is designed to empower financial institutions and fintech startups to innovate with confidence. Our platform provides secure, synthetic data that facilitates rapid evaluation and development, ensuring compliance with data protection laws while eliminating privacy concerns.
By partnering with NayaOne, you can leverage our cutting-edge digital twin in banking technology to unlock new possibilities for innovation and collaboration. With NayaOne, you can accelerate your innovation process, reduce time to market, and deliver superior solutions to your customers.

