
By 2025, privacy laws cover approximately 79% of the global population, with GDPR fines exceeding €5.9 billion cumulatively. In the US, 20 states have enacted comprehensive privacy acts, while regulations like China’s PIPL and emerging Gulf region laws amplify global complexity. For financial institutions, sharing customer data across teams, borders, or vendors remains challenging. Traditional anonymization often degrades data utility by 30 - 50% and retains re-identification risks of up to 15% in certain datasets.
Synthetic data addresses these issues by generating new datasets that replicate statistical patterns without personal identifiers, enabling compliant evaluation and innovation. McKinsey estimates generative AI, bolstered by synthetic data, could unlock $200 - 340 billion in annual value for banking, with up to $1 trillion globally by 2030. Gartner predicts synthetic data will comprise 60% of AI training data by 2024, rising to 80% by 2028, reducing real-data needs by 50%. Early adopters report 40 - 60% faster proof-of-concept (PoC) cycles and enhanced model accuracy. However, challenges like bias amplification and rare event capture must be managed for effective deployment.
1. The Problem
Data fuels financial services innovation, yet it poses significant liabilities including:
- Regulatory Pressure: GDPR, CCPA, PIPL, and the EU AI Act impose stringent compliance requirements, with violations risking budgets and reputations.
- Operational Drag: Securing approvals for live data in PoCs can delay projects by months, hindering agility.
- Failed Workarounds: Anonymisation reduces analytics utility by up to 50% and leaves persistent re-identification risks.
Market Realities:
Source
Key Findings
NIST 2023
Anonymisation degrades data utility by 30 - 50% in financial analytics
Nature 2019
Re-identification risks can reach 15% in anonymised healthcare datasets, applicable to finance
Gartner 2025
85% of AI model failures stem from poor-quality or restricted data
2. The Opportunity
The synthetic data generation market, valued at USD 310 - 576 million in 2024, is projected to grow significantly by 2030 - 2034, with estimates ranging from USD 1.8 - 16.7 billion across sources, driven by CAGRs of 34 - 61%. Growth is pronounced in regulated sectors like banking and healthcare.
Strategic Insights from Industry Leaders:
- McKinsey: Generative AI could add $200 - 340 billion annually to banking, but data constraints limit leverage to 25 - 30% of available data; synthetic data is key to scaling.
- Gartner: By 2025, 10% of decisions will rely on synthetic over real data, addressing governance failures projected in 80% of D&A strategies by 2027.
Benefits for Early Movers:
- Speed: Reduces PoC cycles from months to weeks.
- Reach: Facilitates cross-border evaluation without local data law triggers.
- Accuracy: Balances datasets for underrepresented segments, improving model performance.
- Cost: Scales data without proportional acquisition expenses.
3. The Solution Approach
Synthetic data, artificially generated to replicate real-world datasets without personal identifiers, preserves statistical patterns, edge cases, and relationships, enabling compliant AI and analytics without legal or operational risks. It is created using statistical modelling, AI-driven methods like Generative Adversarial Networks (GANs) or Variational Autoencoders (VAEs), or hybrid approaches combining real and synthetic data for enhanced realism.
In banking, synthetic transaction data achieves 96 - 99% utility equivalence to production data for AML model evaluation, supporting high-stakes compliance use cases. It also advances ethical AI by correcting imbalances in source data (e.g., oversampling underrepresented groups in lending models), though rigorous validation is needed to avoid amplifying biases. In 2025, generative AI enhances correlation capture by 10 - 15%, improving realism for complex financial datasets.
Principles for Financial Services Adoption:
- Privacy-by-Design: Prioritise compliance to meet GDPR, CCPA, and EU AI Act requirements, enabling secure data sharing across borders.
- Use-Case Targeting: Focus on high-value applications like fraud detection, KYC, and AML, as demonstrated by a North American bank using hybrid synthetic-real data to train AML models across four countries without moving personal data.
- Governance Integration: Embed generation and validation in risk frameworks, using secure sandboxes to ensure <5% singling-out risk.
- Bias Management: Actively mitigate biases through pre-generation audits and fairness tools like AIF360, avoiding over-promising utility without rigorous evaluation.
4. Challenges and Mitigations
While powerful, synthetic data has limitations, walking a "fine line between reward and disaster" if not managed. Key challenges include:
Challenge
Impact on Financial Services
Mitigation Strategy
Bias amplification
Perpetuates inequities in lending or fraud models if source data is flawed.
Pre-generation audits and bias-correction tools.
Lack of realism/rare events
Fails to simulate sophisticated fraud or market extremes, leading to model underperformance.
Hybrid approach: Augment with real outliers; use advanced GANs.
High Computational Costs
Resource-intensive for large-scale GANs, limiting scalability in banks.
Cloud-optimised tools like SDV; start with simpler statistical methods.
Quality Issues
May not capture nuances, causing 20 – 30% accuracy drops in complex scenarios.
Rigorous validation; integrate with platforms such as Databricks.
Gartner warns synthetic data risks AI governance if quality is poor, emphasising crisis management.
5. Implementation Guidance
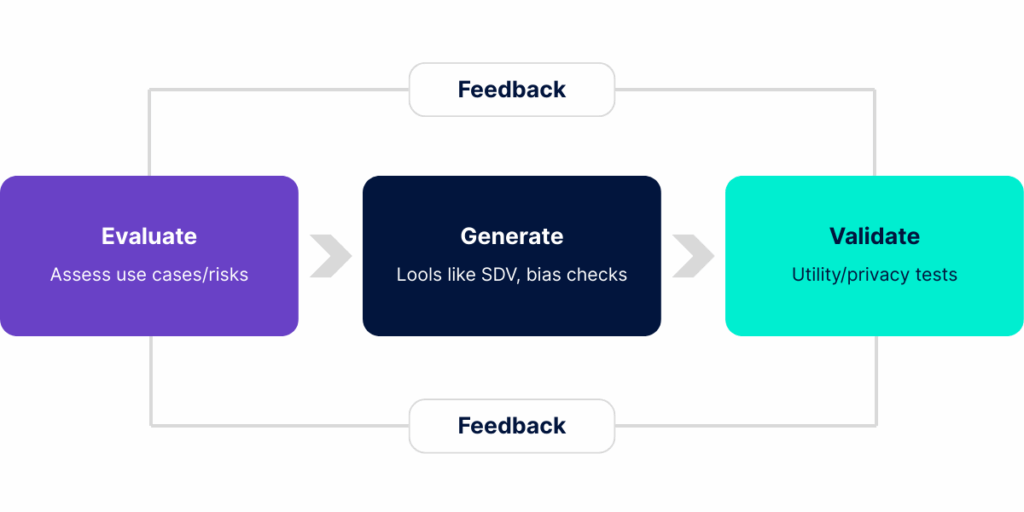
Step 1: Evaluate
Identify privacy-delayed datasets (e.g., fraud, onboarding).
Prioritise by value and risk.
Step 2: Generate
Select methods: SDV/CTGAN for tabular; GANs for unstructured.
- Implement bias checks using tools like AIF360.
Step 3: Validate
Utility tests: Aim for >95% statistical similarity (e.g., KS tests).
Privacy tests: Use Anonymeter for singling-out, linkage, inference risks.
Checklist: Ensure >95% similarity, <5% singling-out risk; integrate with Databricks/Snowflake for scalability.
Common Pitfalls: Over-promising without evaluation; under-investing in validation; ignoring scalability; treating as "set and forget."
6. Evidence and Case Studies
80% of organisations using synthetic data report fewer privacy incidents.
Banks cut PoC timelines by 40 - 60% in sandboxes.
FCA's 2023 - 2025 pilots achieved 60% data similarity in fraud detection, improving models by 15%.
ROI examples: 15 - 20% fraud detection gains, $1 - 2M KYC savings.
Case Studies
North American Bank Reconciliation PoC
- Used synthetic data for multi-vendor evaluation, scaling 10x at no extra cost, cutting timelines by 50% with zero risks.
- Two-thirds of vendors dropped out, highlighting adaptability.
Global Bank KYC PoC
- Synthetic data enabled secure sandbox evaluation, improving pass-through rates by 40% and fraud detection by 15%.
Fraud Detection Pilot (2024 - 2025)
- Synthetic datasets in regulatory sandboxes achieved high fidelity, reducing real-data exposure and supporting model audits under the EU AI Act.
7. Market Trends and Outlook
Synthetic data shifts from niche to mainstream in finance.
Key Trends
- Integration with Databricks/Snowflake and LLMs for compliant training.
- Emerging marketplaces for pre-generated datasets.
- AI agents leveraging synthetic data for complex tasks.
Trends to Watch (Next 12 Months)
- Synthetic data is becoming a must-have for financial institutions. Here are the key trends to watch over the next 12 months, each designed to help banks stay compliant and competitive:
- More Regulatory Support: Regulators like the UK’s Financial Conduct Authority (FCA) are expanding synthetic data use in secure evaluation environments, like sandboxes, to speed up compliance for anti-money laundering (AML) and fraud detection. This means banks can test AI models faster without risking real customer data.
- Easier Validation Tools: New tools are making it simpler to check synthetic data for privacy and accuracy. For example, banks can use these to ensure datasets meet strict standards, like those required for AML model evaluation, with over 95% similarity to real data.
- Stronger AI Reliance: By 2025, 75% of large banks will rely on synthetic data to power AI projects, from fraud detection to customer onboarding, as it bypasses privacy hurdles and cuts costs.
- Global Data Sharing: Banks are forming agreements to share synthetic data across borders safely, enabling collaborative AI development without violating local privacy laws, as seen in recent cross-country AML model training.
These trends signal a clear path: synthetic data is moving from experimental to essential, helping banks innovate while staying compliant.
8. Conclusion and Next Steps
With 85% of AI projects failing due to data issues, synthetic data offers a competitive edge for privacy-proof innovation. Inaction risks slower launches, compliance breaches, and lost market share. Leverage resources like FCA reports, open-source tools and consultancy insights to adopt responsibly.
Next Step: Book a 60-minute NayaOne readiness session at nayaone.com/contact. We’ll map your high-impact use cases and demonstrate validation in a secure, compliant environment - without the six-month data approval wait.