

Varun Resh
Fintech & Emerging Technologies
As the financial services industry becomes more and more digital, large amounts of diverse datasets are needed to fulfil the demands of running innovation programs. One of the critical challenges in this context is the handling of bank-specific and personal data and its processing in innovation initiatives. Synthetic data fuels data-driven innovation and offers a solution to this conundrum. Synthetic data is artificially created and represents an abstraction of real-life data. The abstraction allows financial institutions(FIs) to strip the Personal Identifiable Information(PII) and other sensitive information from real-life data while retaining its statistical properties.
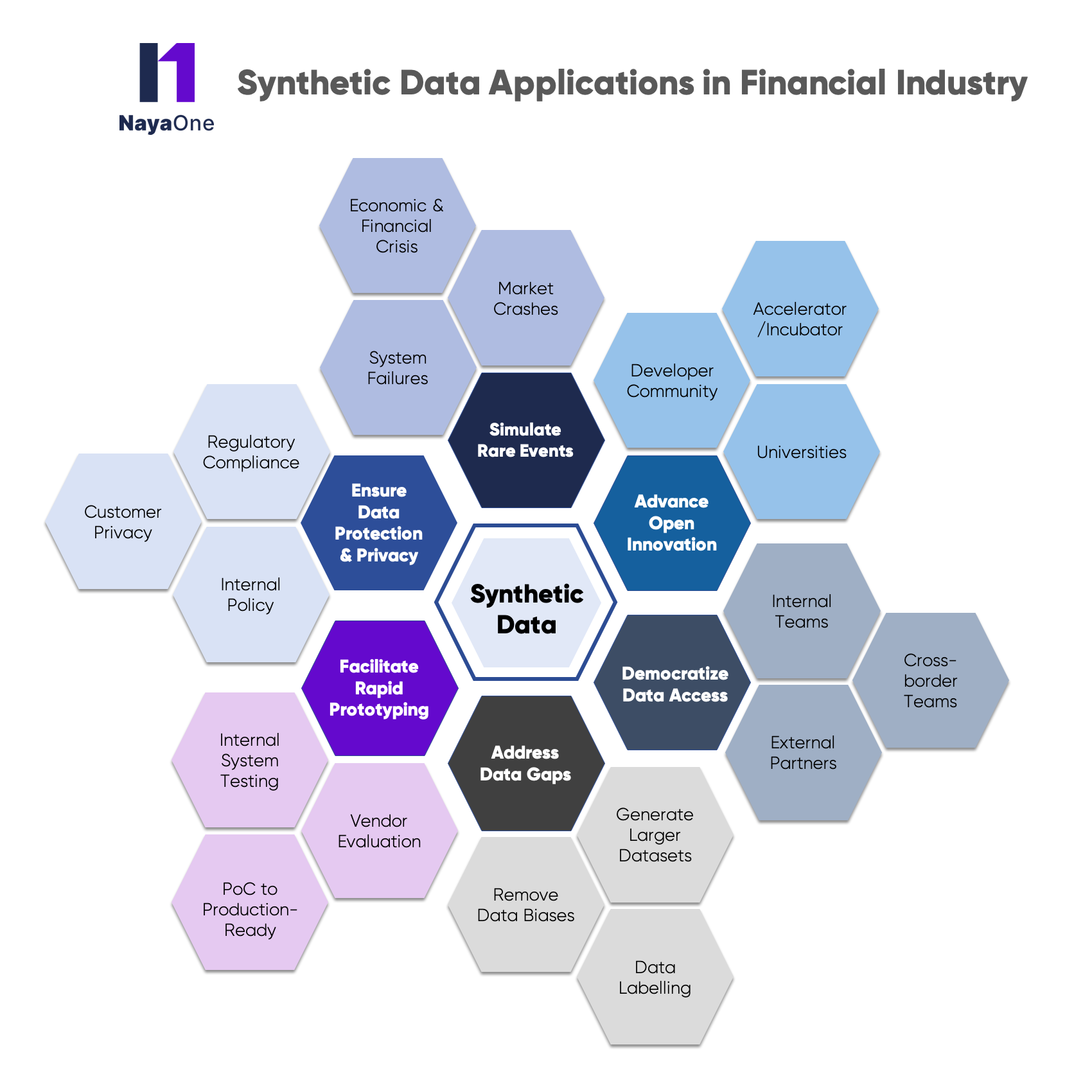
In this blog, we look at different ways in which synthetic data fuels data-driven innovation can help FIs to facilitate and benefit from data-driven innovation:
Advance Open Innovation
Synthetic data allows FIs to embrace Open innovation by enabling them to share synthetic datasets with external innovators and researchers through various ways such as incubators and accelerator programs, partnerships with universities, and running hackathons with developer communities. This sharing allows the collaborative innovation process to be rapid, efficient and valuable for the firm while maintaining compliance requirements.
Democratise Data Access
Data access is a problem not just for the new-age innovators but also for the internal teams from different departments, cross-border teams, and development and support teams of partners. Here also Synthetic data unlocks the doors to share required datasets without going through a maze of approvals and associated time lags.
Address Data Gaps
Synthetic data allows FIs to create new data sets (fully synthetic data) as well as extend existing data sets (partially synthetic data) to fill any existing data gaps. It also allows FIs to remove pre-existing biases from the datasets and generate large amounts of data as per the needs of machine learning models’ training requirements.
Several deep learning models are data-hungry and synthetic datasets are a perfect fit for training these advanced models. In addition to creating large datasets, the creation of labelled datasets is another advantage of Synthetic datasets as they can come in handy in training supervised learning models.
Facilitate Rapid Prototyping
Collecting large amounts of real data is a complicated and time-consuming process in the financial industry. Owing to the speed with which Synthetic datasets can be generated and shared, they are quickly becoming an alternative to facilitate rapid evaluation of internal systems and external vendor evaluation and benchmarking.
synthetic data fuels data-driven innovation and can also be a key enabler in scaling innovation projects from POC to production. Many innovation projects get stranded between POC and full-scale launch due to a lack of varied datasets at different stages of development. Data conditions can be significantly different as the project goes beyond PoC to help leaders judge the utility and value-add of the innovation in real-life scenarios. This is when large amounts of relevant synthetic datasets can help digital leaders turn a POC into a production-ready project that can scale across the business.
Ensure Data Protection & Privacy
Data protection regulations such as GDPR and CCPA may prevent the sharing of financial data both within a company and between institutions. Synthetic data is a great way to ensure data privacy while being able to share data within and across firms without concerns of non-compliance with regulatory requirements.
Privacy-enhancing technologies such as anonymization of sensitive data with traditional data masking techniques before sharing can be susceptible to linkage attacks. Synthetic datasets offer the dual benefit of maintaining privacy as well as utility to resemble real-life datasets required to run innovation projects.
Simulate Rare Events
The financial industry, being a heavily regulated industry, has to undergo several stress tests and be ready for low-probability and high-impact scenarios. Real-life datasets may not be appropriate for these rare and edge-case scenarios such as market crashes, system failures, financial crises, etc. In order to see the effects of these rare events on FI’s systems and analytical models, FIs can rely on synthetic datasets to mimic these rare events and stress conditions.
Data-Driven Innovation with Nayaone’s Synthetic Datasets
NayaOne offers a wide range of synthetic datasets to meet the data needs of your innovation projects. We also offer proprietary and unique synthetic data generation techniques to generate synthetic data from scratch without relying on any real data reserves directly, to avoid data privacy and other issues with generative modelling techniques.

