

Varun Resh
Fintech & Emerging Technologies
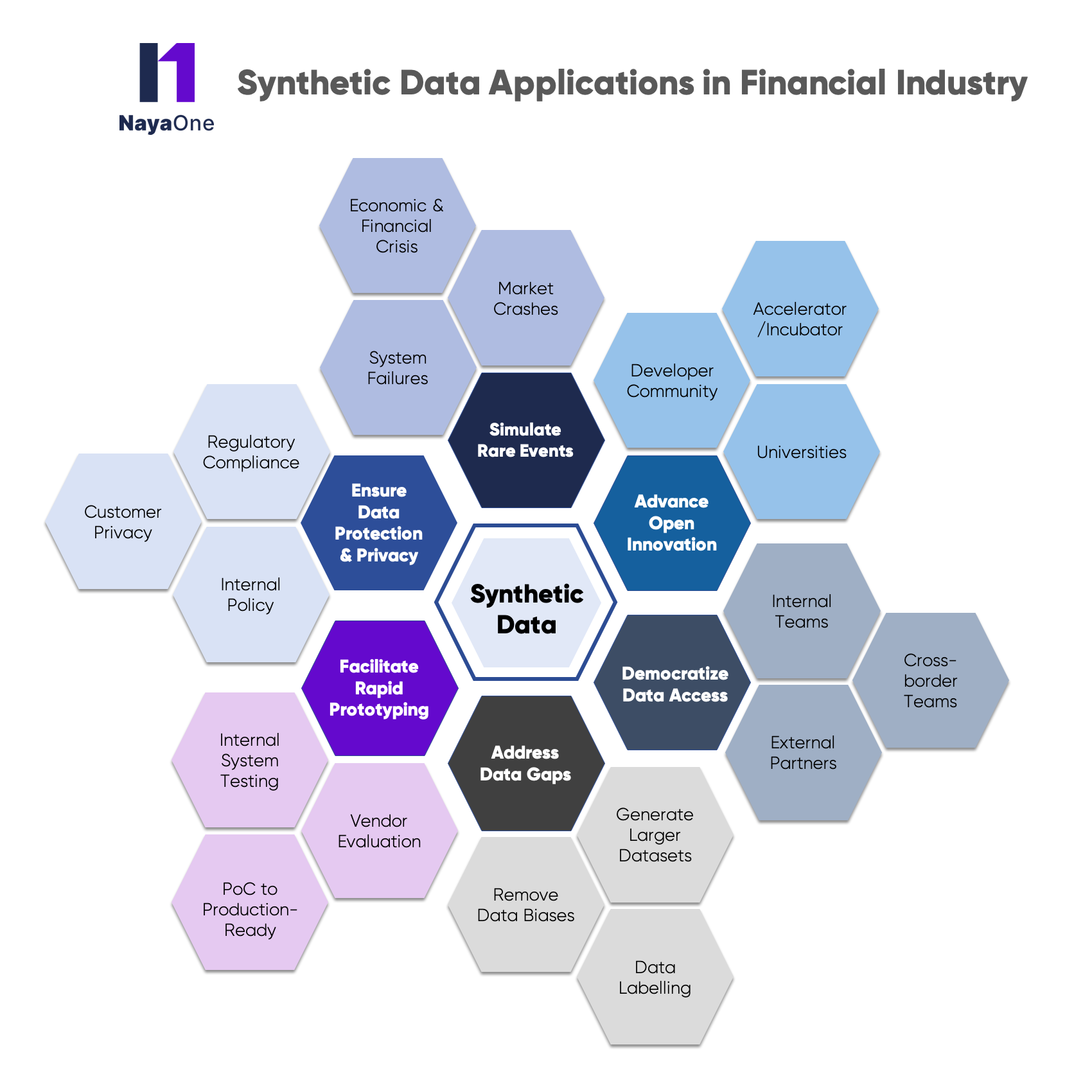
Advance Open Innovation
Synthetic data allows FIs to embrace Open innovation by enabling them to share synthetic datasets with external innovators and researchers through various ways such as incubators and accelerator programs, partnerships with universities, and running hackathons with developer communities. This sharing allows the collaborative innovation process to be rapid, efficient and valuable for the firm while maintaining the compliance requirements.
Democratize Data Access
Address Data Gaps
Facilitate Rapid Prototyping
Ensure Data Protection & Privacy
Privacy-enhancing technologies such as anonymization of sensitive data with traditional data masking techniques before sharing can be susceptible to linkage attacks. Synthetic datasets offer a dual benefit of maintaining privacy as well as utility to resemble real-life datasets required to run innovation projects.
Simulate Rare Events
The financial industry, being a heavily regulated industry, has to undergo several stress tests and be ready for low-probability and high-impact scenarios. Real-life datasets may not be appropriate for these rare and edge-case scenarios such as market crashes, system failures, financial crises, etc. In order to see the effects of these rare events on FI’s systems and analytical models, FIs can rely on synthetic datasets to mimic these rare events and stress conditions.



